Índices Invertidos
Los
índices invertidos son la estructura más utilizada para la recuperación
de palabras. Almacenan cada término y la lista de documentos en los que
este aparece. Esto permite un acceso directo la búsqueda de documentos
asociados cada palabra durante la resolución de consultas. Existen dos
variantes principales: Índice invertido a nivel de registro (record level inverted index) en el que únicamente se almacena la referencia al documento o que contiene la palabra, y Índice invertido a nivel de palabra (word level inverted index) que
adicionalmente guarda la posición del término dentro del documento.
Este último ofrece mayor funcionalidad, sin embargo el tiempo para
crearlo y el espacio para almacenarlo son mucho mayores [4].
Un
índice invertido en su forma más simple esta compuesto por un
vocabulario que es la lista de términos y un posteo que es la lista de
documentos a los cuales estas pertenecen. Para cada modelo de RI el
índice es variado para presentar facilidades específicas a este [1].
Por ejemplo la estructura también puede contener otros datos para cada
termino necesarios para procesar una consulta del usuario, y estos
datos serán diferentes entre cada modelo (los datos requeridos por el
modelo vectorial no son los mismos que los requeridos por el modelo
booleano). En la imagen mostrada a continuación se muestra la forma
básica de un índice invertido:
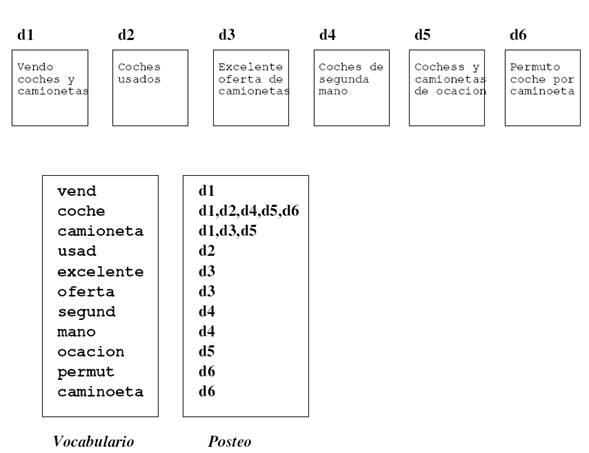
Forma básica de un índice invertido. Tomado de [1].