Mapreduce
Otro algoritmo utilizado para la generación de índices distribuido es el MapReduce. Su idea principal es reducir el trabajo en pequeños fragmentos y distribuirlo entre todas la maquinas. Sus pasos son explicados a continuación [2]:
- Primero se debe designar a un nodo como maestro, para que dirija el proceso global.
- La colección es dividida en pedazos cortos de manera que permitan un rápido procesamiento de cada uno. Esta es la fase llamada Split.
- Luego los pedazos de colección son distribuidos entre las máquinas, de modo que cuando una termina un pedazo se le entrega el siguiente, y así hasta q se acaben todos.
- Cada maquina guarda pares termino-Documento, en archivos locales intermedios (segment files).
- Cómo a cada maquina le llegan varias pedazos de colección, es deseable que todos pares con con el mismo termino se almacenen juntos, así como ir ordenándolos alfabéticamente, para un procesamiento posterior rápido. Esto logrado creando sub archivos para rangos de términos. Por ejemplo: a-f, g-p y q-z. Todas las maquinas tiene la misma división de rangos.
- Luego un inverter asignado a cada rango dentro de los archivos de segmento (Por ejemplo existe uno diferente para a-f, g-p y q-z). Entonces toma los datos de esas particiones de todas las maquinas y las ordena y unifica en una única lista de posteo.
En la figura siguiente se muestra una representación grafica de este algoritmo:
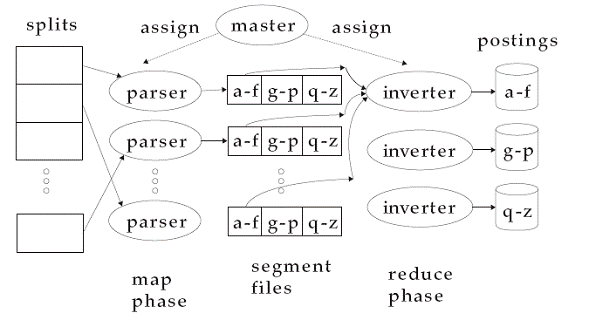
Creación de índice invertido distribuido utilizando MapReduce. Tomado de [2]